Understanding workflow nodes
Introduction
In the last section about expressions, we thought of workflows in Cargo as layers of various data objects stacked on top of each other. These data objects are called nodes.
Nodes linked in a flow together execute one by one, creating an execution flow, where each node is only aware of other nodes appearing previously in the execution flow.
The logic is dictated by the following principles:
- Linear progression: Nodes within a workflow are linked in uni-directional manner, ensuring each node is executed one after the other.
- Node awareness and dependencies: A node is only aware of nodes that have preceded it in the execution flow. This means any given node can access the outputs or results of its predecessors but remains unaware of subsequent nodes or their outcomes.
What is a node
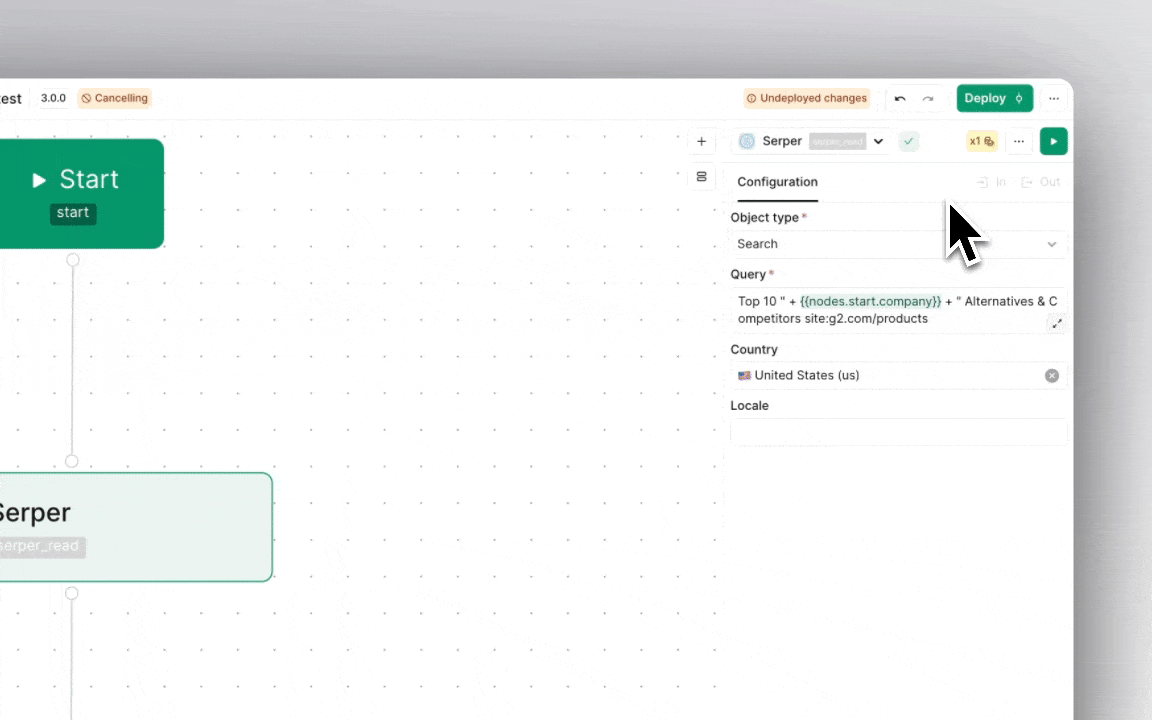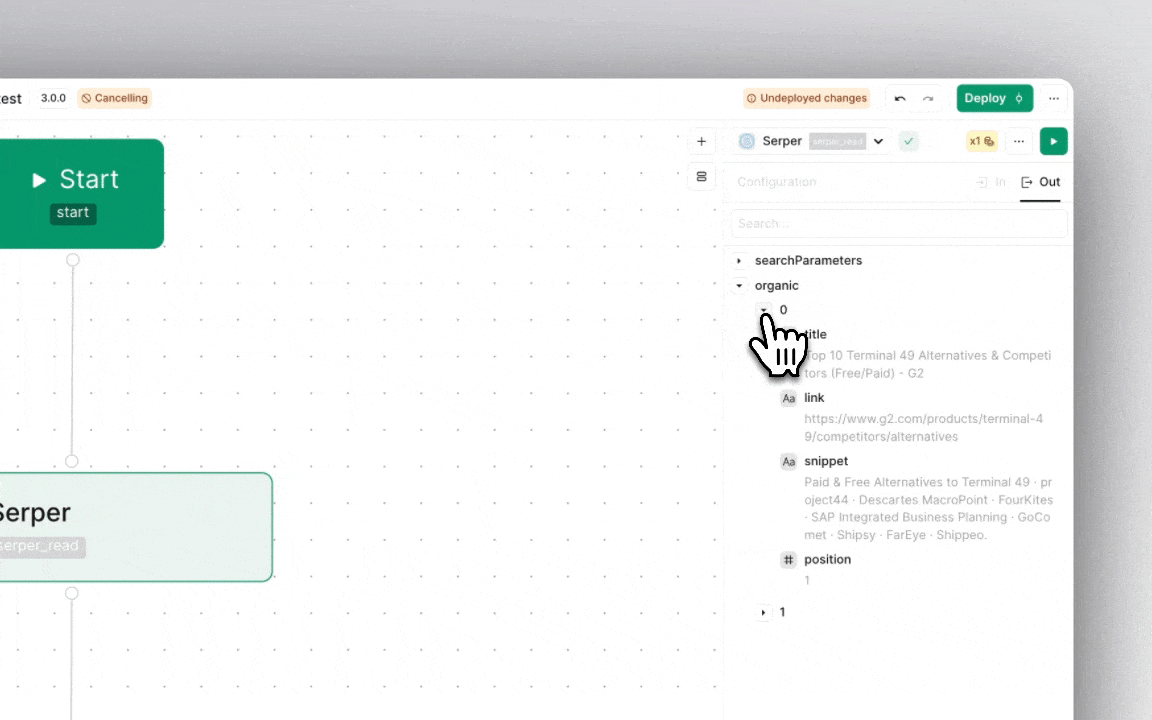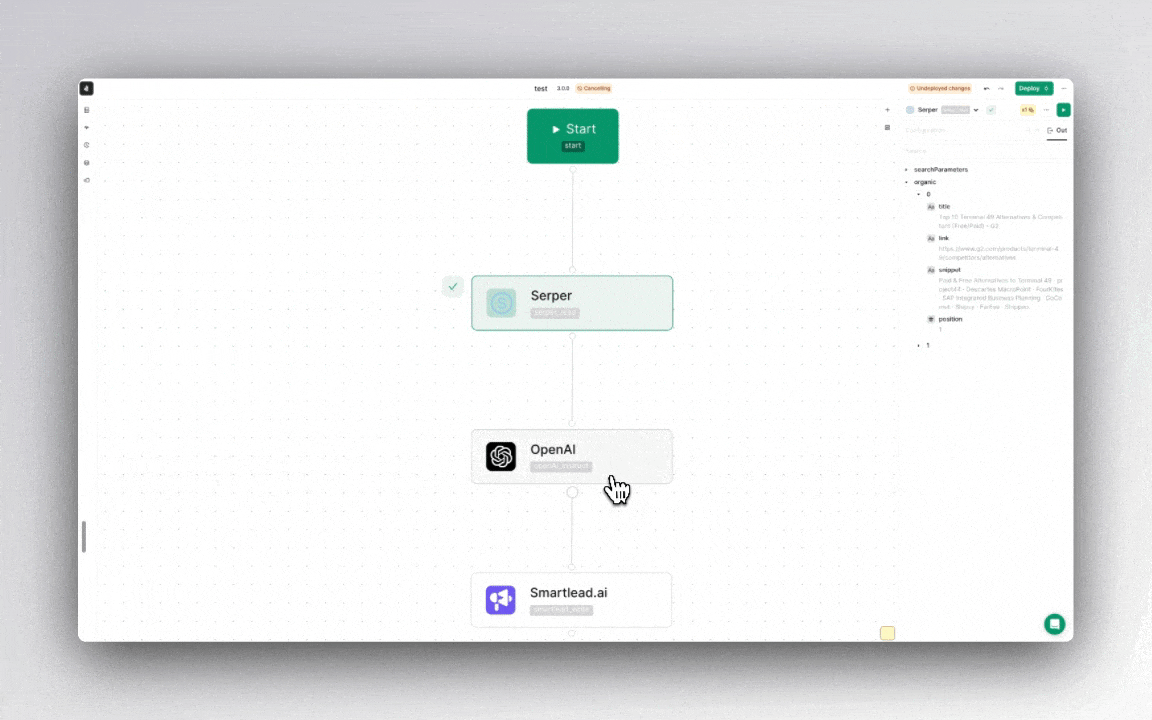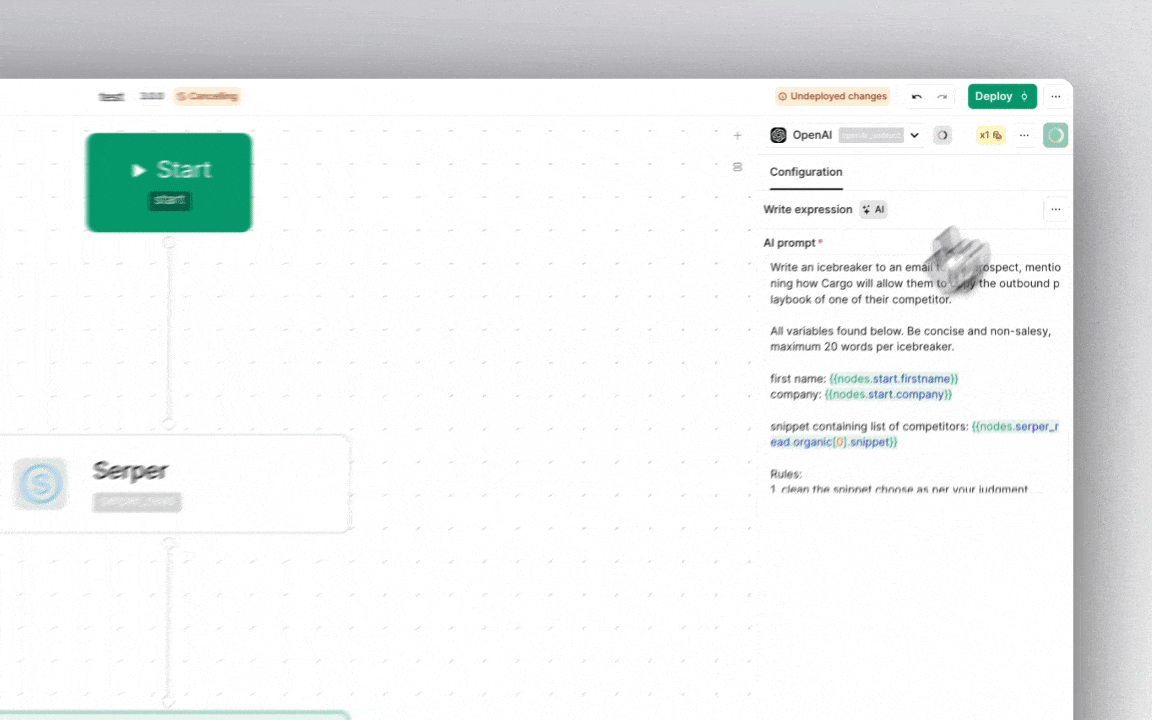
Think of each node like a little helper that can contain data or execute the logic in an expression.
When you execute a workflow, each of these helpers ('nodes') does its job ('run') and passes along the result ('output'), which is a bit of data ('object') that is output from the job.
Each node has properties, such as a unique 'name', 'execution state', 'fallback logic' in case a run fails, etc. that are either constant or created during a run.
Some nodes can carry smaller helpers inside them, called 'mappings', 'fields' or 'filters', which also contain data for the node.
'Core' Cargo nodes are largely logical functions that can execute preset logic within Cargo's environment. An example is the filter node, which creates an if-else condition without the user having to define the entire if-else boilerplate logic. Another node can 'trigger' a different workflow while passing a JSON object as an output.
Most nodes are built on top of integrations, aka connectors to 3rd-party tools like Salesforce, Clearbit, or Slack, etc.
These execute logic and pass data to and from the API endpoints configured for these connectors, and will often require access either via API keys or Cargo 'credits'.
Each node is thus almost always calling upon an API endpoint at the back to allow an action to take place, such as fetching data, writing data, or searching data. The display of a node is thus purposefully designed to simplify the user experience, hiding the complexity of the API call and the data transformation that happens behind the scenes. For this reason, the appearance of every node core node or connector can vary, depending on the type of action it performs for the user.
Nodes action types

Nodes perform various actions based on their type:
- Read nodes: Used to fetch data associated with a certain key. For example, a read node for ZoomInfo returns an enriched data object associated with a contact passed to it.
- Enrich nodes: Used to enrich data with additional information. For example, an enrich node for Clearbit enriches a contact with additional information like company name, industry, etc.
- Write nodes: Used to write data from a connector. For example, a write node for Outreach connector creates a contact in Outreach.
- Search nodes: Receive a search term and filter through a dataset to find matching records, typically available for CRM or enrichent connectors like Salesforce and Apollo, respectively.
- Associate nodes: Map an object from one data type to another, such as associating a HubSpot contact with a HubSpot account.
Node data types
Nodes hold, by default, a data object similar to a 'JSON' (JavaScript Object Notation). This is intentionally standardized to allow simplicity in the expressions template while referencing different nodes and their constituent data objects.
These data objects can in turn be of different data types such as 'String', 'Number', 'Boolean', or 'Array', allowing nodes to store and manipulate various kinds of information useful in the execution flow.
Any property inside such data objects can be accessed using dot notation.
Node states
Understanding the various states that nodes can inhabit throughout the lifecycle of a workflow is essential for both the construction and troubleshooting of nodes inside a workflow.
- Linked vs. unlinked: Unlinked nodes within a workflow are inert, i.e. isolated, unable to receive or pass on information in the execution flow. Linking nodes ensures that the execution flow can proceed from one node to the next.
- Run vs. unrun: Each node within a workflow can exist in one of two states: 'unrun' or 'run'. The 'unrun' state indicates that the node has not yet participated in the execution flow. The 'run' state signifies that the node has successfully executed its logic.

- Successful run: A node's run can either be 'successful', 'erroring',
'pending', or 'canceled'. A successful run indicates that the node has executed
its logic without any issues, producing an
INandOUTproperty. - Unsuccessful run:
Erring nodes are typically flagged with an error banner, a visual cue signaling
an issue during the run. An unsuccessfully run node often results in an empty
output object, indicating a failure to produce the expected data or result.
Conversely, however, an empty output doesn't imply that the node errored, for
instance a search node can return an empty output even if successfully executed,
if no matching records were found as per the specification.
- Unsuccessful run:
Erring nodes are typically flagged with an error banner, a visual cue signaling
an issue during the run. An unsuccessfully run node often results in an empty
output object, indicating a failure to produce the expected data or result.
Conversely, however, an empty output doesn't imply that the node errored, for
instance a search node can return an empty output even if successfully executed,
if no matching records were found as per the specification.
The start node
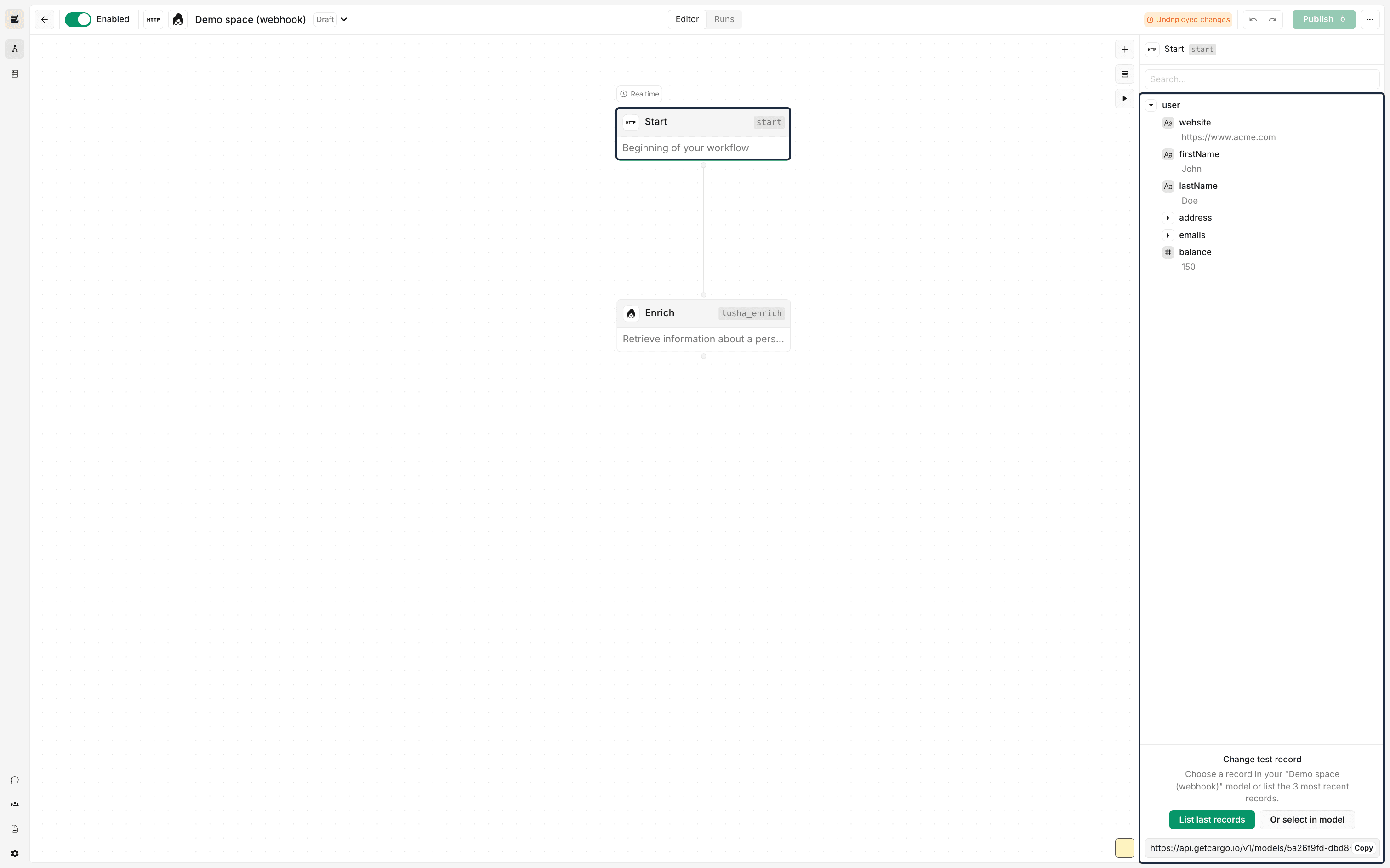
The start node is always present in every Cargo workflow. Subsequent nodes can reference the start node to access its data mappings.
It is critical, as it always stores at least one data object representing a record from all the records it has access to, known as the 'test sample'.
The sample gives the user an idea of how the incoming data will be shaped, enabling them to write the appropriate expressions and test them with the values in the sample record.